Ứng dụng trí tuệ nhân tạo giải quyết "bài toán" dịch tự động văn bản chữ Nôm sang chữ Quốc ngữ
20-04-2023Website chuyển tự (dịch) tự động từ chữ Nôm sang chữ Quốc ngữ góp phần bảo tồn và phát huy các giá trị văn hóa truyền thống của dân tộc, đặc biệt có thể được ứng dụng ngay để phát triển phần mềm dịch thuật trên thiết bị di động nhằm phục vụ du khách khi tham quan, tìm hiểu các địa điểm có sử dụng chữ Nôm.
Có thể khẳng định rằng, chữ Nôm là thể loại chữ viết tay đầu tiên của người Việt Nam do các bậc tiền nhân xây dựng dựa trên chất liệu của chữ Hán, được sử dụng trong gần 1.000 năm từ thế kỷ X đến thế kỷ thứ XIX. Trong suốt 10 thế kỷ đó, rất nhiều công trình về lịch sử, văn học, y học, nông nghiệp, địa lý, … đã được biên soạn, viết bằng chữ Nôm và còn được lưu giữ cho đến ngày nay.
"Tuy nhiên, phần lớn tài liệu chữ Nôm vẫn chưa được dịch (chuyển tự) sang chữ Quốc ngữ sử dụng con chữ Latin, và thực tế là hiện khá ít người có khả năng đọc được chữ Nôm để tìm hiểu, khai thác kho tàng văn hóa, tri thức, tư liệu lịch sử do người xưa để lại", PGS.TS Đinh Điền (Trường Đại học Khoa học Tự nhiên - ĐHQG TP.HCM) cho biết.
Vì thế, nhóm chuyên gia đang công tác tại Trường Đại học Khoa học Tự nhiên - ĐHQG TP.HCM đã triển khai nhiệm vụ khoa học - công nghệ "Xây dựng hệ thống chuyển tự tự động văn bản chữ Nôm sang chữ Quốc ngữ" với mục tiêu then chốt là xây dựng hệ thống có khả năng dịch tự động chữ Nôm sang chữ Quốc ngữ.
Theo lời PGS.TS Đinh Điền, việc chuyển tự chữ Nôm sang chữ Quốc ngữ rất phức tạp do hai hệ chữ khác loại hình chữ viết. Chữ Nôm thuộc loại hình chữ ghi ý (ideographic), còn chữ Quốc ngữ thuộc loại hình chữ ghi âm vị (phonemic). Cùng một chữ Nôm có thể được dịch sang nhiều chữ Quốc ngữ khác nhau tùy theo tri thức văn hóa, lịch sử, địa lý, tiếng Việt cổ, tiếng địa phương, từ chuyên ngành,…
Hay nói cách khác, việc chọn chữ Quốc ngữ nào cho bản dịch cần phải suy đoán, và việc suy đoán này phải sử dụng đến nhiều "tri thức" cả trong và ngoài ngôn ngữ (extra-linguistic).
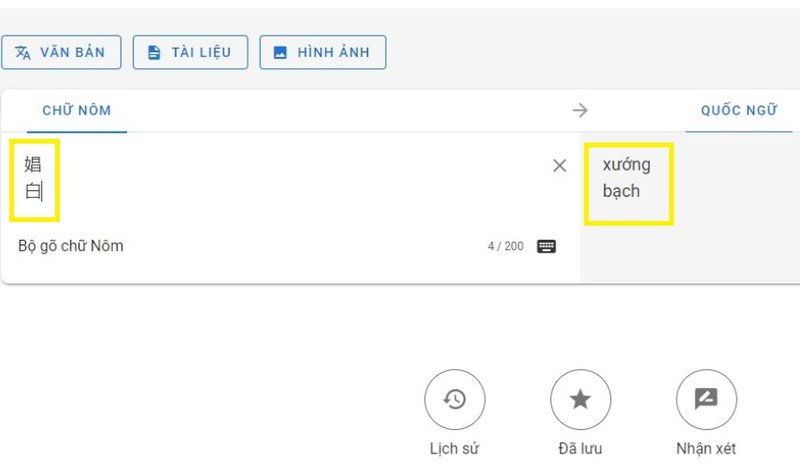
Giao diện website chuyển tự tự động chữ Nôm sang chữ Quốc ngữ là sản phẩm của nhiệm vụ khoa học - công nghệ
"Khó khăn lớn nhất trong việc chuyển tự chữ Nôm sang chữ Quốc ngữ chính là việc chọn chữ Quốc ngữ đúng trong số các chữ Quốc ngữ khả dĩ của chữ Nôm", đại diện nhóm triển khai nhiệm vụ thông tin, "Việc chọn lựa này phụ thuộc vào ngữ cảnh, thể loại (văn xuôi/vần), lĩnh vực (văn học, y học, tôn giáo, …) và cả vào niên đại, vùng miền.".
Do đó, vì nguyên tắc của học máy là nếu hệ thống/con người huấn luyện cho máy tính ngữ liệu thuộc thể loại, lĩnh vực nào thì máy sẽ dịch tốt hơn với những văn bản thuộc thể loại/lĩnh vực đó.
Báo cáo trước Hội đồng tư vấn nghiệm thu nhiệm vụ vừa được Sở KH&CN TP.HCM tổ chức, PGS.TS Đinh Điền khẳng định: gần đây với sự phát triển vượt bậc của lĩnh vực trí tuệ nhân tạo (AI) cũng như các công nghệ học máy (machine learning) tiên tiến trong ngành khoa học máy tính đã giúp bài toán chuyển tự tự động hay chuyển tự máy (machine transliteration) có thể thực hiện được, dù chưa thể chính xác hoàn toàn.
Với công nghệ học máy, máy có thể "tự học" được cách chọn (suy đoán) chữ Quốc ngữ phù hợp với từng chữ Nôm thông qua ngữ cảnh trong rất nhiều các bản dịch Nôm - Quốc ngữ trước đó của con người. Do đó, nếu hệ thống "dạy" cho máy tính bằng cách cung cấp (đưa vào kho ngữ liệu huấn luyện) cho máy càng nhiều bản dịch Nôm - Quốc ngữ chuẩn, thì máy sẽ càng "thông minh" hơn và cho kết quả dịch chính xác hơn. Ngoài ra, máy cũng có khả năng tự học để hoàn thiện hơn bằng cách rút kinh nghiệm từ các lỗi dịch sai của máy sau khi con người hiệu đính lại những chỗ dịch sai đó. Quá trình này nếu được lặp lại càng nhiều thì máy sẽ càng cho những bản dịch tốt hơn sau này.
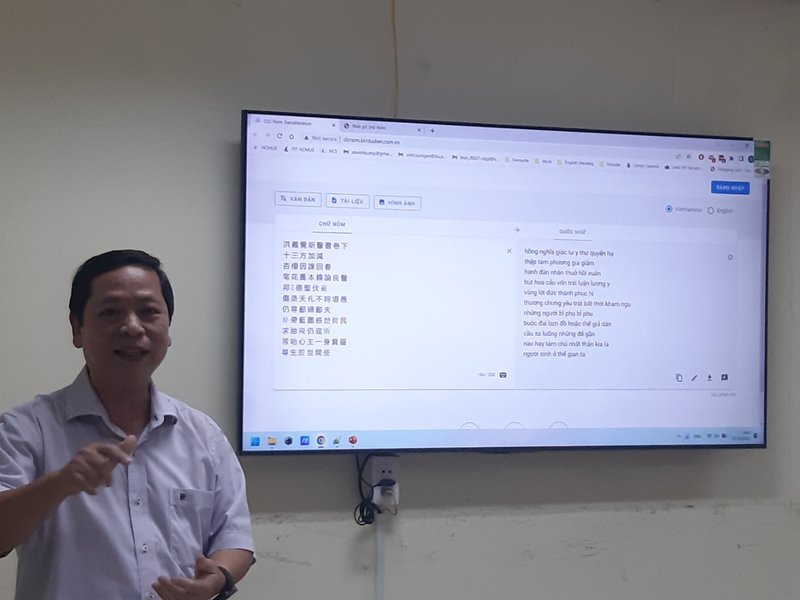
PGS.TS Đinh Điền thuyết minh và vận hành thị phạm tính năng chuyển tự tự động văn bản chữ Nôm sang văn bản chữ Quốc ngữ tại Hội đồng tư vấn nghiệm thu nhiệm vụ khoa học - công nghệ do Sở KH&CN TP.HCM tổ chức
Kết hợp "học máy" với mô hình ngôn ngữ
Trên tinh thần đó, trong phạm vi của nhiệm vụ, nhóm các nhà khoa học với sự dẫn dắt của PGS.TS Đinh Điền đã đề xuất và hoàn thiện việc xây dựng hệ thống chuyển tự tự động từ chữ Nôm sang chữ Quốc ngữ bằng công nghệ học máy có bổ sung thêm tri thức từ điển và mô hình ngôn ngữ theo lĩnh vực.
Cụ thể, PGS.TS Đinh Điền (chủ nhiệm nhiệm vụ) cho biết, tận dụng công nghệ học sâu (deep learning), nhóm các nhà khoa học tại gia Trường Đại học Khoa học Tự nhiên - ĐHQG TP.HCM đã tập trung dịch một chiều từ chữ Nôm sang chữ Quốc ngữ. Cụ thể, nhóm xây dựng Tự điển chữ Nôm - Quốc ngữ (bản chất là một tập hợp có hệ thống các Nôm tự được giải nghĩa Quốc ngữ) nhằm tập trung giải nghĩa của từng tự, cung cấp các thông tin sâu về mặt ngôn ngữ học.
Số lượng Nôm tự rút trích được từ kho ngữ liệu chữ Nôm và các nguồn tham khảo đạt 22.264 mục tự. Sau đó, xây dựng tiếp Từ điển chữ Nôm - Quốc ngữ chứa 6.198 mục từ. Nhóm cũng xây dựng Tự điển chữ Hán - Việt chứa 26.330 mục tự và Từ điển chữ Hán - Việt chứa 66.450 mục từ.
|
"Tự" là đơn vị nhỏ nhất trong quá trình xử lý ngữ liệu để chuẩn bị cho quá trình chuyển tự. Cấp độ lớn hơn "tự" là từ và cụm từ. Một từ hay cụm từ có thể gồm hai, ba, đến bốn tự. Cao hơn từ và cụm từ là cấp độ câu. Câu có thể bao gồm câu thơ hoặc câu văn xuôi với độ dài thay đổi tùy văn bản thu thập được. |
Mô hình được nhóm triển khai nhiệm vụ đề xuất và hiện thực là dựa trên mô hình hiện hữu của giải pháp dịch máy thống kê SMT bằng Moses của giải pháp Nôm Converter (www.chunom.org) mà PGS.TS Đinh Điền và các cộng sự từng nghiên cứu trước đó với một số khác biệt và cải tiến dựa trên kinh nghiệm hệ dịch Hoa - Việt bằng thống kê và Anh - Việt bằng học sâu cũng của chính nhóm nghiên cứu, đó là thay vì dịch cả hai chiều (từ chữ Nôm sang chữ Quốc ngữ và ngược lại) như hệ thống Nôm Converter, thì nhóm nghiên cứu chỉ tập trung dịch một chiều từ chữ Nôm sang chữ Quốc ngữ vì thấy thấy chiều ngược lại không có ý nghĩa thực tiễn lớn.
Ngoài ra, việc dịch một chiều từ chữ Nôm sang chữ Quốc ngữ sẽ giúp dễ tập trung cải tiến chất lượng đầu ra của chữ Quốc ngữ hơn bằng cách đầu tư nhiều cho mô hình ngôn ngữ (Language Model) của chữ Quốc ngữ.
Để khắc phục tình trạng thiếu chữ Nôm trong tập huấn luyện như trong hệ thống Nôm Converter, nhóm triển khai nhiệm vụ bổ sung tự điển Hán - Việt vào bảng dịch (phrase table) của hệ thống Moses. Ngoài ra, nhóm cũng bổ sung nhiều bản dịch (thủ công) song song Nôm - Quốc ngữ khác (mà hệ thống Nôm Converter chưa đưa vào huấn luyện) để nâng cao chất lượng dịch.
"Cải tiến chính của nhóm nghiên cứu là phân chia theo lĩnh vực cho ngữ liệu huấn luyện ở đầu vào và mô hình ngôn ngữ chữ Quốc ngữ ở đầu ra", PGS.TS Đinh Điền nhấn mạnh.
"Khó khăn lớn nhất trong việc chuyển tự chữ Nôm sang chữ Quốc ngữ chính là việc chọn chữ Quốc ngữ đúng trong số các chữ Quốc ngữ khả dĩ của chữ Nôm đó. Việc chọn lựa này phụ thuộc vào ngữ cảnh, thể loại, lĩnh vực và cả vào niên đại. Hệ thống hiện hữu chỉ mới chọn chữ Quốc ngữ theo ngữ cảnh có trong tập ngữ liệu huấn luyện mà tập huấn luyện này lại được huấn luyện chung (lẫn lộn thể loại, lĩnh vực, niên đại)", PGS.TS Đinh Điền cho biết thêm, "Vì vậy, trong mô hình đề xuất, chúng tôi phân chia tập huấn luyện, cũng như mô hình ngôn ngữ theo thể loại và lĩnh vực.".
PGS.TS Đinh Điền cho biết, mục đích quan trọng nhất là tra cứu nghĩa Quốc ngữ tương ứng của các Nôm tự. Để đạt được điều này, xét về cấu trúc vi mô, tự điển chữ Nôm phải được xây dựng một cách có hệ thống thành các trường thuộc tính cụ thể. Đó là, trường nghĩa Quốc ngữ, là trường căn bản luôn có, giải nghĩa Quốc ngữ cho mục Nôm tự; trường tần suất: cho biết mức độ phổ biến của Nôm tự; trường lĩnh vực: cho biết ngữ cảnh cụ thể của Nôm tự; và trường thể loại: cung cấp thêm thông tin về nguồn gốc Nôm tự. Việc xây dựng tự điển chữ Nôm - Quốc ngữ bao gồm giai đoạn thu thập, xây dựng kho ngữ liệu chữ Nôm, từ đó trích xuất danh sách các Nôm tự và hoàn thiện cấu trúc vĩ mô, vi mô của tự điển.
Để huấn luyện máy học và xây dựng mô hình ngôn ngữ, trong công trình nghiên cứu vừa được nghiệm thu này, PGS.TS Đinh Điền và cộng sự đã xây dựng ngữ liệu cho lĩnh vực văn học, đời sống và tôn giáo.
"Mỗi lĩnh vực có những vốn từ khác nhau, giúp chúng ta giới hạn lại miền/lĩnh vực lựa chọn chữ Quốc ngữ (trong trường hợp chữ Nôm đa trị) để nâng cao khả năng chọn đúng được chữ Quốc ngữ tương ứng", PGS.TS Đinh Điền phân tích, "Cuối cùng, thay vì chỉ lấy ngữ liệu chữ Quốc ngữ trong tập huấn luyện để huấn luyện cho mô hình ngôn ngữ (quá ít, chỉ vài ngàn câu), nhóm nghiên cứu chủ động sử dụng thêm ngữ liệu chữ Quốc ngữ ở bên ngoài (rất lớn, hàng triệu câu) và đã được phân chia theo thể loại và lĩnh vực nói trên để huấn luyện cho mô hình ngôn ngữ N-gram của chữ Quốc ngữ ở đầu ra nhằm nâng cao khả năng chọn đúng chữ Quốc ngữ theo tính tự nhiên nhất của ngôn ngữ. Được biết, kho ngữ liệu đơn ngữ chữ Quốc ngữ được nhóm nghiên cứu "nạp dạy" cho hệ thống hiện ở mức 823.533 câu và 13.024.774 từ.
Vì nguyên tắc của học máy là nếu chúng ta huấn luyện cho máy tính hiểu được/biết được ngữ liệu thuộc thể loại, lĩnh vực nào thì máy sẽ dịch tốt hơn với những văn bản thuộc thể loại hay lĩnh vực đó.
Trên tinh thần này, khi triển khai/áp dụng đi vào thực tế, người sử dụng muốn dịch văn bản thể loại hay lĩnh vực nào, chỉ cần chọn (trên trình đơn) thể loại hay lĩnh vực muốn dịch để máy tính lựa chọn kiến thức đã học phù hợp với thể loại hay lĩnh vực mà máy đã được huấn luyện. Trong trường hợp người sử dụng không xác định được thể loại hay lĩnh vực của văn bản chữ Nôm cần dịch, thì máy tính vẫn có thể tự xác định (chế độ tự động - auto) thể loại hay lĩnh vực của văn bản đó trước khi dịch (tựa như chức năng chọn ngôn ngữ tự động của công cụ Google Translator).
Là một phần của nhiệm vụ, PGS.TS Đinh Điền và nhóm cộng sự đã xây dựng thành công mô hình ngôn ngữ và mô hình dịch trên những ngữ liệu thu thập được, đồng thời hoàn thiện thử nghiệm website hỗ trợ chuyển tự (dịch) tự động từ chữ Nôm sang chữ Quốc ngữ (tạm thời được đặt tại địa chỉ http://clcnom.kimtudien.com.vn/), và bộ công cụ "dịch máy" này cũng đã được nhóm triển khai nhiệm vụ trình diễn, báo cáo trước Hội đồng tư vấn nghiệm thu nhiệm vụ khoa học - công nghệ do Sở KH&CN TP.HCM tổ chức.
Được biết, ngay trong đầu tháng 4/2023 này, Trường Đại học Khoa học Tự nhiên và nhóm nghiên cứu đã đưa hệ thống chuyển tự chữ Nôm nói trên lên website chính thức của trường (https://tools.clc.hcmus.edu.vn/) nhằm phục vụ nhu cầu tra cứu của đông đảo người dân, các nhà khoa học và các tổ chức, doanh nghiệp.
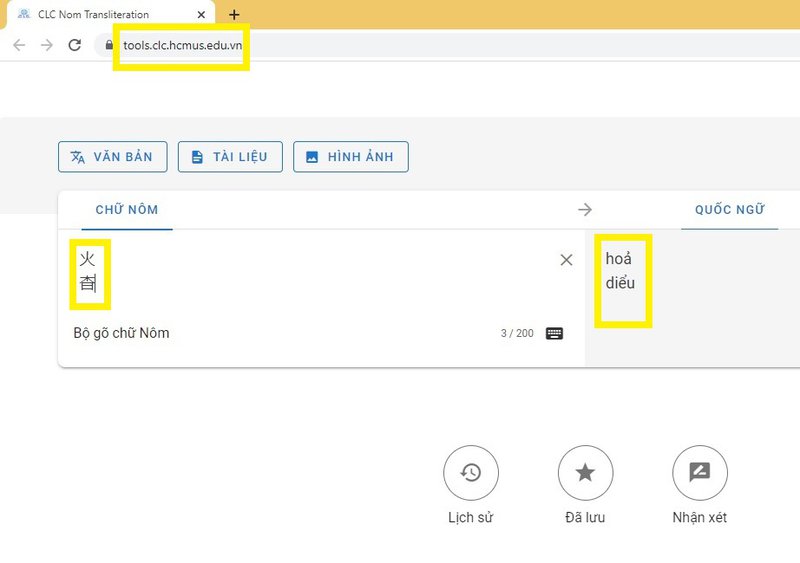
Giao diện trang chủ bộ công cụ chuyển tự chữ Nôm đã được trường Đại học Khoa học Tự nhiên công bố chính thức trên website nhà trường
Về cơ bản, phần mềm giao diện website chuyển tự tự động chữ Nôm sang chữ Quốc ngữ đi kèm bộ gõ chữ Nôm tích hợp, cho phép người dùng chọn lĩnh vực (văn học, lịch sử, tôn giáo) và thể loại (văn xuôi, văn vần) của ngữ liệu đầu vào. Các kết quả thực nghiệm bản dịch văn bản chữ Nôm sang chữ Quốc ngữ với bản dịch chữ Quốc ngữ (bản gốc) được đánh giá là chuẩn xác ở mức cao.
Cũng theo lời nhóm phát triển, giải pháp dịch văn bản chữ đã hoàn thành, hiện nay, nhóm đang tiếp tục phát triển thêm khối (module) nhận dạng văn bản ảnh (bằng cách chụp hình chữ Nôm thay vì phải gõ vào hay dán vào) hay còn gọi là OCR (Optical Character Recognization). Khối nhận dạng này sẽ được tích hợp vào hệ thống chuyển tự hiện nay để qua đó du khách có thể dịch nội dung của các tài liệu, hình ảnh (liễn, câu đối, bia) được viết bằng chữ Nôm thường thấy ở các khu di tích, đền đài,… chỉ bằng camera của điện thoại di động.
Xa hơn nữa, cũng theo lời nhóm nghiên cứu, chúng ta hoàn toàn có thể xây dựng một website đảm nhận dịch vụ chức năng tìm kiếm, tra cứu văn bản chữ Nôm một khi có sự liên kết với các kho lưu trữ văn bản chữ Nôm trong và ngoài nước.
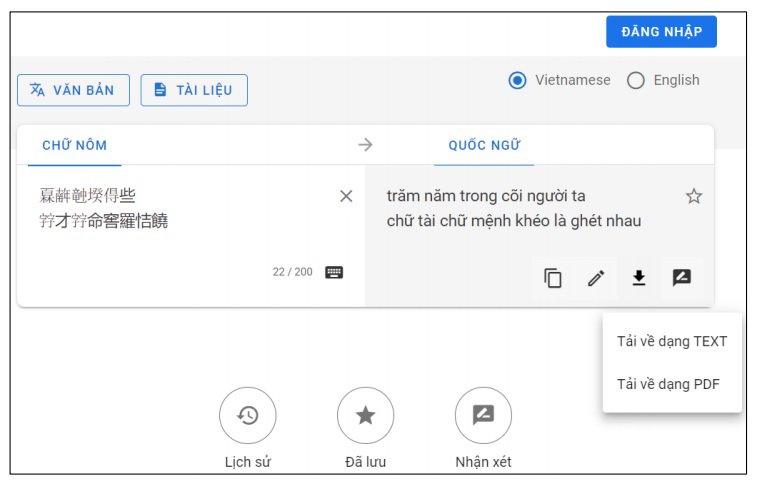
Giao diện trang chủ website chuyển tự chữ Nôm
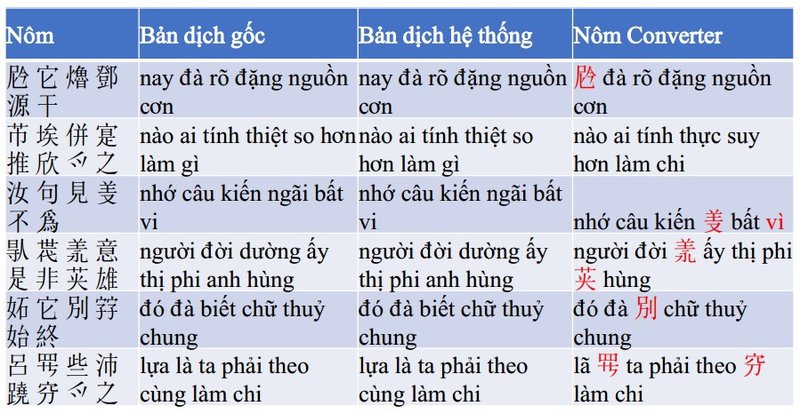
Kết quả thử nghiệm (chuyển ngữ lĩnh vực văn học) được thực hiện vào ngày 26/12/2022
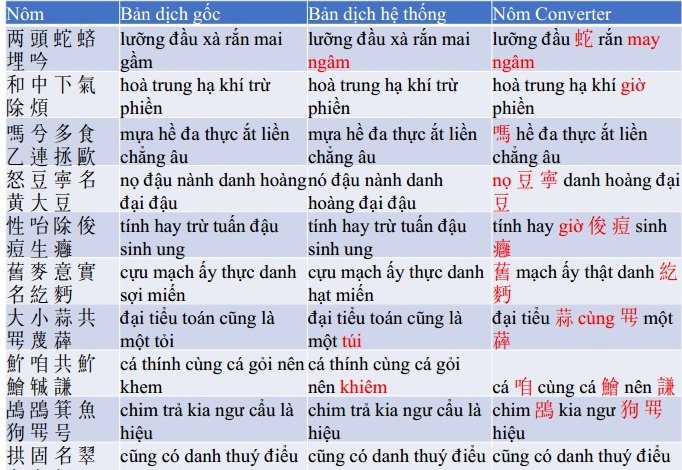
Kết quả thử nghiệm (chuyển ngữ lĩnh vực y học) được thực hiện vào ngày 26/12/2022
Tựu trung, kết quả của nhiệm vụ "Xây dựng hệ thống chuyển tự tự động văn bản chữ Nôm sang chữ Quốc ngữ" do Trường Đại học Khoa học Tự nhiên (ĐHQG TP.HCM) chủ trì đã mở ra hướng tiếp cận mới và nhiều tiềm năng cho nhu cầu chuyển ngữ các tài liệu bằng chữ Nôm phục vụ nhu cầu tra cứu, khai thác kho tàng chữ Nôm trong lĩnh vực văn hóa, văn học, y học dân tộc, lịch sử, địa lý, nông nghiệp, và đặc biệt hơn hết là góp phần bảo tồn và phát huy các giá trị văn hóa truyền thống của dân tộc.
|
Thông tin liên hệ: Trường Đại học Khoa học Tự nhiên (ĐHQG TP.HCM) Địa chỉ: 227 Nguyễn Văn Cừ, quận 5, TP.HCM Số điện thoại: 090 827 8207 - (028) 38 354 266 Email: ddien@hcmus.edu.vn - clc@hcmus.edu.vn |


